graph LR;
C[/Input Statement/] --> LSP_D1(Identify</br>descriptive</br>interpretations);
LSP_D1 --> LSP_D2(List</br>descriptive</br>interpretations);
LSP_D2 --> LSP_Neg1(Formulate</br>negations);
C --> LSP_A1(Identify</br>descriptive</br>interpretations);
LSP_A1 --> LSP_A2(List</br>descriptive</br>interpretations);
LSP_A2 --> LSP_Neg2(Formulate</br>negations);
C --> LSP_N1(Identify</br>normative</br>interpretations);
LSP_N1 --> LSP_N2(List</br>normative</br>interpretations);
LSP_N2 --> LSP_Neg3(Formulate</br>negations);
LSP_Neg1 --> CP1[/Interpretation<br/>Pair 1/];
LSP_Neg2 --> CP2[/Interpretation<br/>Pair 2/];
LSP_Neg3 --> etc[/.../];
💡 The EvidenceSeeker Pipeline: Basic Ideas & Concepts
EvidenceSeeker Boilerplate is a Python code template that can be used to set up EvidenceSeeker as LLM-based fact-checking tools.
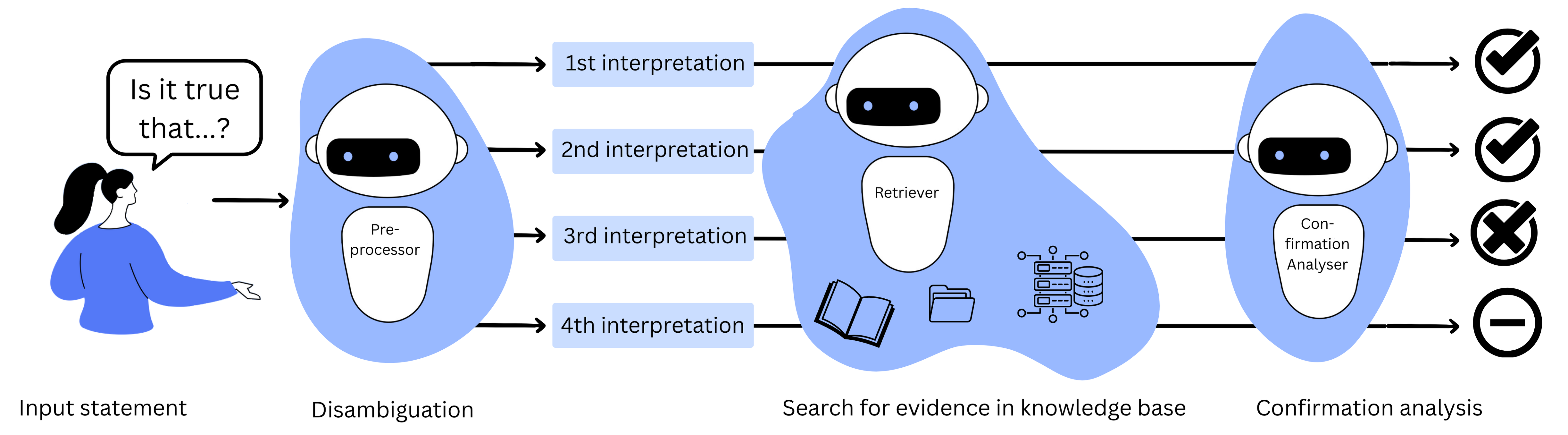
Each EvidenceSeeker relies on its knowledge base to fact-check input statements. For each input statement, the EvidenceSeeker searches for confirming and debunking information in the knowledge base and aggregates the found evidence. An EvidenceSeeker uses a pipeline with three main components:
- Preprocessor: The preprocessor disambiguates the input statement by identifying different interpretations.
- Retriever: The retriever searches for potential evidence in the knowlege base by identifying relevant data (i.e., semantically similar) to the identified interpretations.
- Confirmation Analysis: The confirmation analyser decides for each potential piece of evidence the degree to which it confirms or debunks an identified interpretation. Finally, the confirmation analyser aggregates the found evidence for each identified interpretation to an overall degree of confirmation.
TipFact-Checking Accuracy
Whether an EvidenceSeeker can be used to fact-check a statement accurately depends on the accuracy and completeness of the knowledge base. If the EvidenceSeeker cannot find any evidence for or against the input statement, it does not necessarily mean there is no evidence for or against it. There might, for instance, exist evidence for the statement in question, which is, however, not documented in the knowledge base. Similarly, even if an EvidenceSeeker finds confirming (or debunking) evidence for a statement, it does not mean that the statement is true (or false). The evidence might be outdated or erroneous.
1. Preprocessor
Statements are often formulated ambiguously or vaguely. In such cases, the truth of a statement might crucially depend on the chosen interpretation. The EvidenceSeeker is designed to deal with ambiguity in the following way: Instead of fact-checking the input statement as it is, the preprocessor is tasked with identifying different interpretations before searching for relevant information in the knowledge base. In the following pipeline steps, the retriever and confirmation analyser will then analyse each found interpretation separately.
In particular, the preprocessor will identify different interpretations and categorise them according to the following three statement types:
- Descriptive statements: Statements that contain factual or descriptive content.
- Normative statements: Statements that contain value judgements, recommendations, or evaluations
- Ascriptive statements: Statements that ascribe a given statement to a person or organisation by stating, for instance, that someone believes, denies, doubts or utters something.
These distinctions are crucial for fact-checking: Descriptive statements can typically be checked through factual knowledge provided by science or testimonials. The assessment of normative statements is more difficult. There is even a philosophical debate about whether normative statements can have truth-values. For these complications, the EvidenceSeeker pipeline will refrain from further analysing normative interpretations in its default configuration. Ascriptive statements are specific descriptive statements that warrant special treatment. Consider, for instance, the sentence Trump believes climate change is not human-made. While it might be true that Trump is a climate sceptic, the belief content is certainly false. The ascription might be accurate, while the content of the belief is false.
The Preprocessor in Detail
Figure 1 depicts the preprocessor’s internal pipeline. Each process node represents a step, in which the language model is instructed to analyse the input in a specific way: For each statement type, the model is first asked to find interpretations of this type and then to list them in a structured way. Then, the model is prompted to formulate the negation for each found interpretation. The resulting interpretation pairs (each pair consisting of a found interpretation and its negation) represent the preprocessor’s output, which is the input for the retriever component.
2. Retriever
For each found interpretation, the retriever will search for relevant data in the indexed knowledge base and return the k most relevant documents from the knowledge base. If the retriever receives, say, three found interpretations as input, it will retrieve in sum \(3*k\) documents (k can be configured via the parameter top_k and is set to \(8\) by default; see here for details).
graph LR;
KB1[(Knowledge base)]-->R1;
CP1[/ i-th interpretation<br/>pair/] --> R1(Retrieve</br>relevant documents);
R1 --> O1[/i-th interpretation pair<br/>+<br/>1st relevant document/];
R1 --> O2[/i-th interpretation pair<br/>+<br/>2nd relevant document/];
R1 --> O3[/i-th interpretation pair<br/>+<br/>.../];
R1 --> O4[/i-th interpretation pair<br/>+<br/>k-th relevant document/];
3. Confirmation Analyser
For each interpretation of the input statement found, the confirmation analyser will analyse the degree of confirmation of each relevant document for the interpretation. This will result in \(k\) analyses for each interpretation, which will be aggregated into one overall confirmation assessment for each interpretation. The confirmation analyser will summarise its results for each interpretation I by assigning one out of three levels of confirmatory power:
- Strong confirmation: The interpretation I is strongly confirmed by the information found in the knowledge base.
- Confirmation: The interpretation I is confirmed by the information found in the knowledge base.
- Weak confirmation: The interpretation I is weakly confirmed by the information found in the knowledge base.
- Inconclusive confirmation: The interpretation I is neither confirmed nor disconfirmed by the information found in the knowledge base.
- Weak disconfirmation: The interpretation I is weakly disconfirmed by the information found in the knowledge base.
- Disconfirmation: The interpretation I is disconfirmed by the information found in the knowledge base.
- Strong disconfirmation: The interpretation I is strongly disconfirmed by the information found in the knowledge base.
Note
The EvidenceSeeker pipeline will not aggregate its analyses for each found interpretation into one overall assessment of the input statement. Instead, it will end with an independent assessment for each found interpretation. This is motivated by the view that the fact-checking results depend crucially on the interpretation of the input statement.
The Confirmation Analyser in Detail
graph LR;
ID1[/i-th interpretation pair</br>+</br>1st relevant document D1/];
ID1 --> IA11(Confirmatory</br>analysis of I</br>w.r.t. D1)
ID1 --> IA12(Confirmatory</br>analysis of non-I</br>w.r.t. D1)
IA11 --> AG1(Degree of </br>confirmation for the</br>i-th intepretation</br>w.r.t. D1)
IA12 --> AG1
ID2[/i-th interpretation pair</br>+</br>2nd relevant document D1/];
ID2 --> IA21(Confirmatory</br>analysis of I</br>w.r.t. D2)
ID2 --> IA22(Confirmatory</br>analysis of non-I</br>w.r.t. D2)
IA21 --> AG2(Degree of </br>confirmation for the</br>i-th intepretation</br>w.r.t. D2)
IA22 --> AG2
ID3[/i-th interpretation pair<br/>+<br/>.../];
ID3 --> IA31(...)
ID3 --> IA32(...)
IA31 --> AG3(...)
IA32 --> AG3
ID4[/i-th interpretation pair</br>+</br>k-th relevant document Dk/];
ID4 --> IA41(Confirmatory</br>analysis of I</br>w.r.t. Dk)
ID4 --> IA42(Confirmatory</br>analysis of non-I</br>w.r.t. Dk)
IA41 --> AG4(Degree of </br>confirmation for the</br>i-th intepretation</br>w.r.t. Dk)
IA42 --> AG4
AG1 --> AG(Confirmation</br>aggregation)
AG2 --> AG
AG3 --> AG
AG4 --> AG
AG --> R[/"Overall level of </br>confirmation for the</br>i-th intepretation"/]
The internal pipeline of the confirmation analyser is depicted in Figure 3 and proceeds along the following steps:
- Confirmatory analysis w.r.t. each relevant document:
- Each interpretation pair comprises two statements: \(I\) and \(\textit{non-I}\). The statement \(I\) formulates the identified interpretation; \(\textit{non-I}\) formulates its negation.
- For each found relevant document \(D\), the model is separately asked to analyse the confirmatory relation between \(D\) and \(I\), and between \(D\) and \(\textit{non-I}\). More precisely, the model is prompted to decide whether \(D\)
- provides sufficient evidence to support the \(I\) (\(\textit{non-I}\)),
- provides evidence that contradicts \(I\) (\(\textit{non-I}\)), or whether
- it neither supports nor contradicts \(I\) (\(\textit{non-I}\)).
- The EvidenceSeeker will then gauge the degree of confirmation \(DOC\) between \(D\) and \(I\) in the following way: It takes the token probability of the first answer option (\(A_1\)) w.r.t. \(I\) and subtracts the token probability of \(A_1\) w.r.t. \(\textit{non-I}\). The resulting value \(DOC(D,I):=Prob(A_1;I,D)-Prob(A_1;\textit{non-I},D)\) is interpreted as the degree of confirmation of the interpretation \(I\) w.r.t. \(D\). It can take values between \(-1\) and \(1\), where \(-1\) would mean maximal disconfirmation by \(D\), \(1\) maximal confirmation and \(0\) inconclusive confirmation.
- Confirmation aggregation: In a second step, the degrees of confirmation for each document will be aggregated into an overall degree of confirmation for each interpretation by taking the mean over all documents \(D\) for which \(|DOC(D,I)|>0.2\) (\(DOC(I):=1/n \sum_D DOC(D,I)\) with \(n\) being the number of relevant documents for \(I\) with \(|DOC(D,I)|>0.2\)). Finally, the numerical value \(DOC(I)\) is translated into an overall level of confirmation for interpretation \(I\) in the following way:
- \(0.6 < DOC(I) \leq 1\): strong confirmation
- \(0.4 < DOC(I) \leq 0.6\): confirmation
- \(0.2 < DOC(I) \leq 0.4\): weak confirmation
- \(-0.2 \leq DOC(I) \leq 0.2\): inconclusive confirmation
- \(-0.4 \leq DOC(I) < -0.2\): weak disconfirmation
- \(-0.6 \leq DOC(I) < -0.4\): disconfirmation
- \(-1\leq DOC(I) < -0.6\): strong disconfirmation
Explainability & Transparency
EvidenceSeeker are designed to be transparent and explainable:
- Open Source: EvidenceSeeker Boilerplate is an open-source project, which means that the code, the underlying algorithms, and the prompts used are publicly available. This allows others to inspect the code, understand the inner workings of the pipeline, and contribute to its development.
- Traceability: Each component of the EvidenceSeeker Boilerplate pipeline (preprocessor, retriever, confirmation analyser) is designed to be modular and understandable. In particular, users can trace the result of the fact-checking process back to the input-output pairs of each step in the pipeline. These include:
- the different interpretations of the input statement found by the preprocessor,
- the relevant documents the retriever fetched from the knowledge base as potential evidence for an interpretation, and
- the degree of confirmation the confirmation analyser outputs for each interpretation based on the retrieved item of potential evidence.
- Model openness: The EvidenceSeeker Boilerplate can be used with models of your choosing. In particular, it can be configured to use open-weight LLMs, in which case the models’ internal parameters are publicly available. This means that others can inspect and assess the model’s behaviour and scrutinise its performance with different evaluation metrics.
To what extent an EvidenceSeeker instance is explainable and transparent depends on whether these features are faithfully conferred to the EvidenceSeeker instance and, in particular, whether EvidenceSeeker Boilerplate is used with open models. We believe that fact-checking is a crucial and sensitive task that requires transparency and explainability since users should be able to understand why certain statements are problematic according to truth standards.